Financial Data Lakes for Efficient Data Management
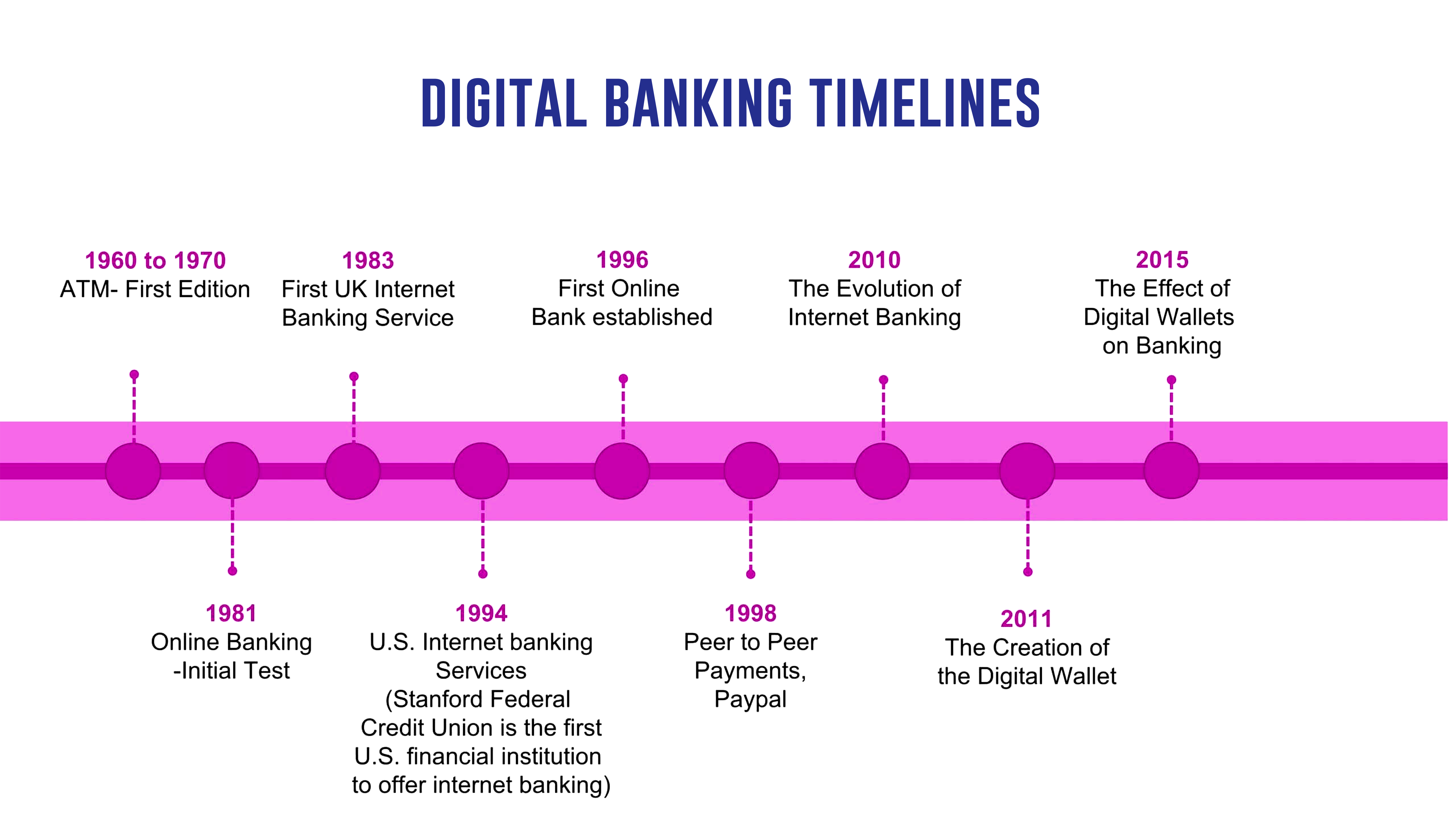
As of 2024, over 80% of leading financial institutions have adopted or are implementing financial data lakes to revolutionize their data management strategies. This significant statistic underscores the pivotal role of financial data lakes in enabling banks to navigate the complexities of massive data volumes, diverse data types, and the pressing need for real-time analytics. In this context, understanding the strategic deployment of financial data lakes, complemented by industry insights and examples from pioneering banks, becomes crucial for C-suite executives aiming to harness data for competitive advantage.
As banks grapple with the deluge of data generated from digital transactions, customer interactions, and regulatory reporting, the traditional data warehouses are being outpaced. With their ability to store vast amounts of structured and unstructured data, financial data lakes offer a flexible, scalable solution. This blog explores the strategic importance of financial data lakes for banks, underpinned by industry insights and examples from leading financial institutions.
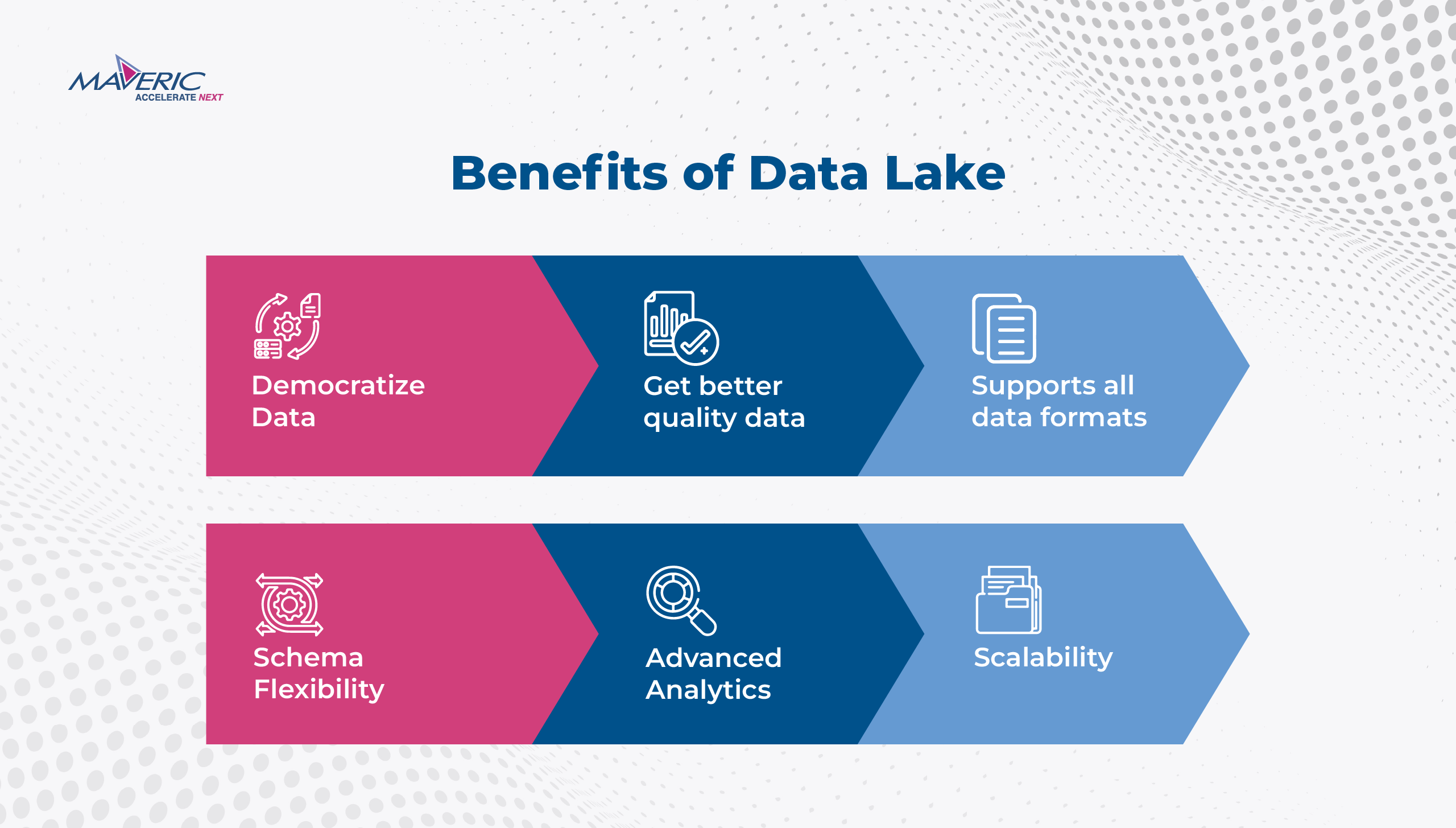
The Strategic Imperative of Financial Data Lakes
Financial data lakes allow banks to consolidate all their data into a single repository, where it can be easily accessed, analyzed, and managed. This holistic approach to data storage enhances operational efficiency and unlocks new insights, driving innovation and competitive advantage. A report by McKinsey highlights that banks leveraging data lakes effectively can see a 10% increase in revenue through personalized offerings and improved risk management.
For instance, JPMorgan Chase has invested in building a robust financial data lake that integrates data from across its global operations. This strategic move has enabled the bank to enhance its real-time analytics capabilities, offering customers more personalized services and streamlining risk management processes.
Advantages of Data Lakes Engineering Services
Data lake engineering services are crucial in successfully implementing financial data lakes. These services encompass data lakes’ design, development, and maintenance, ensuring they are optimized for performance, security, and compliance. The flexibility of data lakes to handle various data formats and the scalability to accommodate growing data volumes make them an ideal solution for financial institutions dealing with diverse data sets.
Goldman Sachs’ adoption of data lake engineering services has facilitated the integration of AI and machine learning algorithms into its data management processes. This integration has significantly improved the bank’s ability to generate actionable insights, enhancing decision-making and operational efficiency.
Data Lake Financial Services: A Game-Changer
Data lake financial services have emerged as a game-changer in the banking sector, enabling institutions to leverage their data assets more effectively. These services include advanced analytics, customer segmentation, fraud detection, and regulatory compliance reporting. Financial data lakes provide a unified view of data and provide more profound insights into customer behavior, market trends, and operational risks.
Citibank’s implementation of a financial data lake has revolutionized its approach to fraud detection. By analyzing transaction data in real-time, the bank can identify and mitigate fraudulent activities more effectively, protecting its customers and reducing financial losses.
Overcoming Challenges in Data Lake Implementation
While financial data lakes offer numerous benefits, their implementation is challenging. Data governance, quality, and security are critical concerns that banks must address to ensure the integrity and confidentiality of their data. A comprehensive data governance framework is essential for managing access, ensuring data quality, and complying with regulatory requirements.
Bank of America has tackled these challenges head-on by establishing strict data governance policies and investing in state-of-the-art security technologies. This proactive approach has enabled the bank to maintain high data quality standards and ensure robust security in its financial data lake, fostering trust among its customers and stakeholders.
Strategies for the Future
As banks continue to navigate the complexities of the digital landscape, several strategies will be vital to maximizing the benefits of financial data lakes:
1) Invest in Talent and Technology:
Building a team of data science and engineering experts equipped with the latest tools and technologies is crucial for developing and managing an effective financial data lake.
2) Foster a Data-Driven Culture:
Encouraging a culture that values data-driven decision-making across the organization can enhance the adoption and utilization of financial data lakes.
3) Enhance Data Governance:
Implementing robust data governance practices is essential for ensuring data quality, security, and compliance, particularly in the highly regulated banking sector.
4) Leverage AI and Machine Learning:
Integrating AI and machine learning algorithms can unlock deeper insights from the data stored in financial data lakes, driving innovation and competitive advantage.
5) Prioritize Security and Compliance:
Investing in advanced security measures and staying abreast of regulatory changes are critical for protecting data and maintaining compliance.
Conclusion
Implementing financial data lakes represents a strategic imperative for banks in the digital era. By offering a scalable, flexible solution for data management, financial data lakes enable banks to enhance operational efficiency, drive innovation, and maintain a competitive edge. Leading financial institutions have already begun reaping the benefits of their data lake investments, setting a benchmark for the industry. As we look to the future, banks that continue to invest in financial data lakes, supported by solid data governance, talent, and technology, will be well-positioned to lead in the data-driven banking landscape.
About Maveric Systems
Established in 2000, Maveric Systems is a niche, domain-led, BankTech specialist, transforming retail, corporate, and wealth management digital ecosystems. Our 2600+ specialists use proven solutions and frameworks to address formidable CXO challenges across regulatory compliance, customer experience, wealth management and CloudDevSecOps.
Our services and competencies across data, digital, core banking and quality engineering helps global and regional banking leaders as well as Fintechs solve next-gen business challenges through emerging technology. Our global presence spans across 3 continents with regional delivery capabilities in Amsterdam, Bengaluru, Chennai, Dallas, Dubai, London, New Jersey, Pune, Riyadh, Singapore and Warsaw. Our inherent banking domain expertise, a customer-intimacy-led delivery model, and differentiated talent with layered competency – deep domain and tech leadership, supported by a culture of ownership, energy, and commitment to customer success, make us the technology partner of choice for our customers.
View