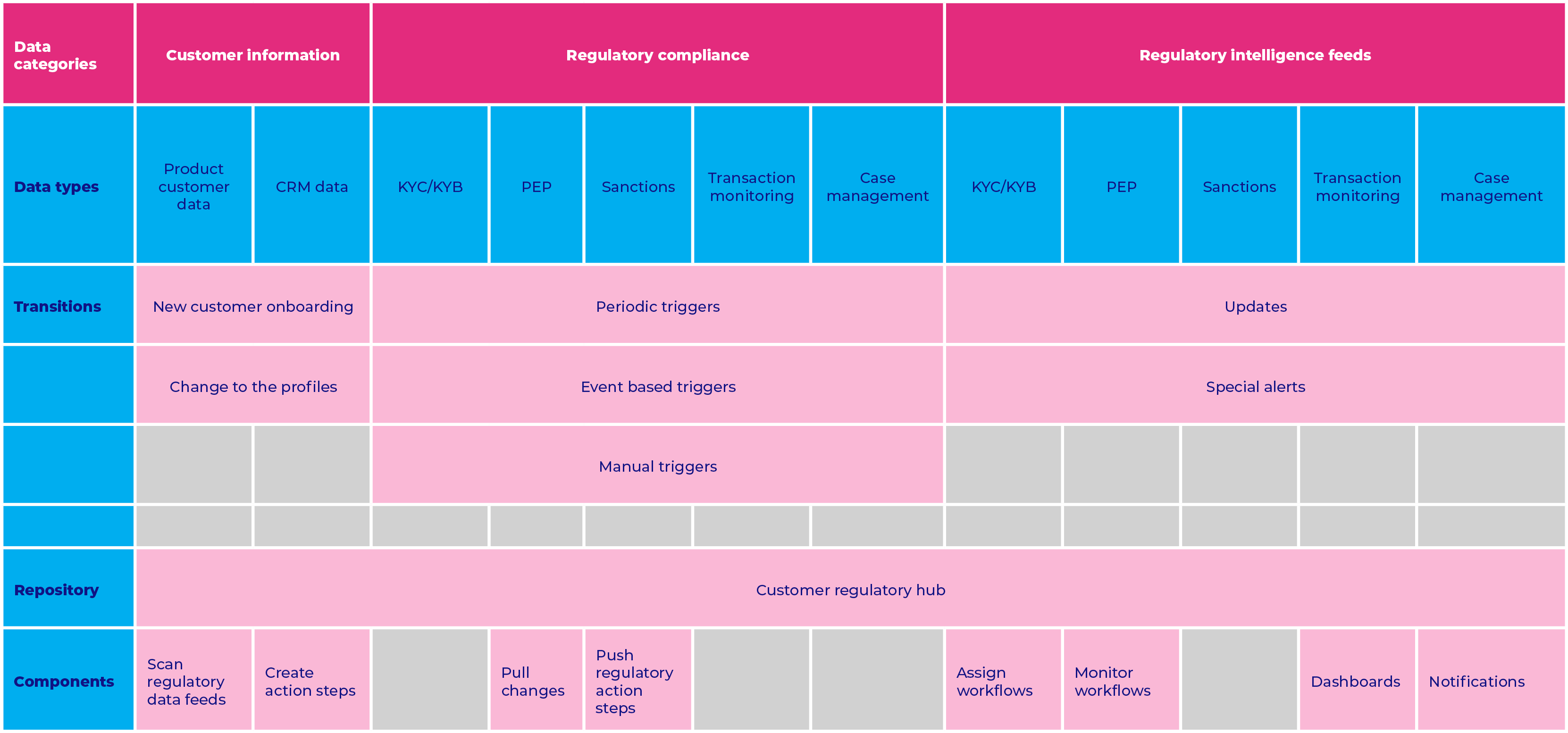
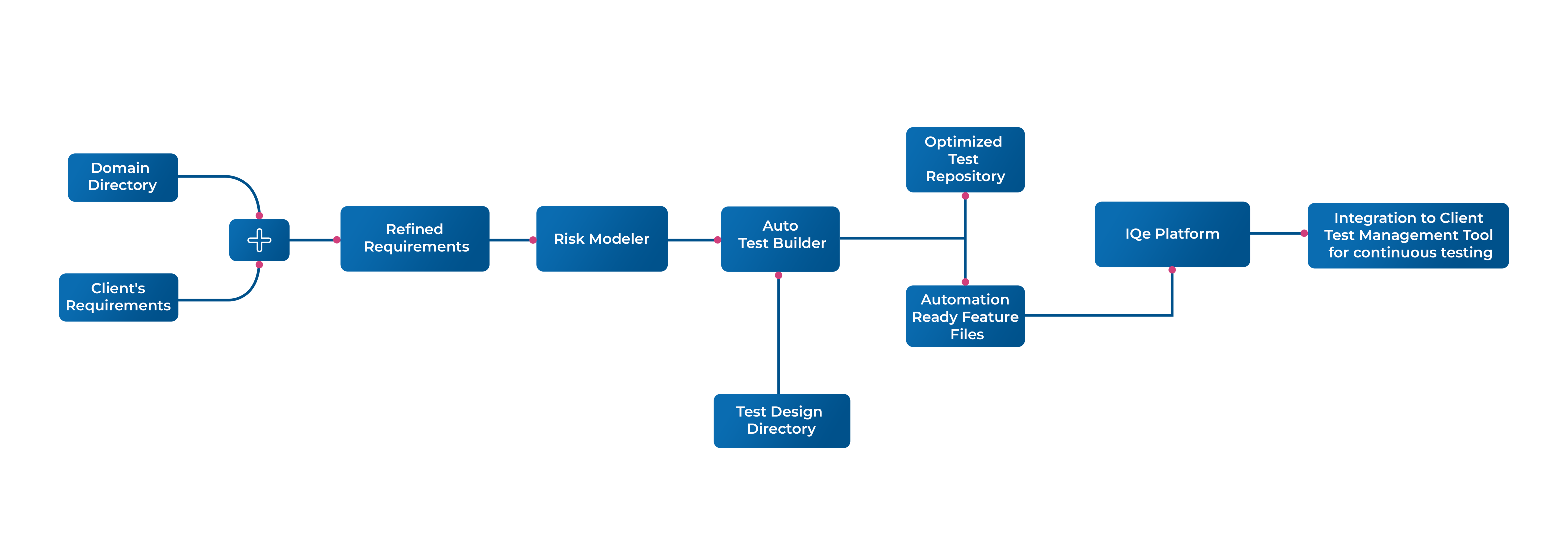
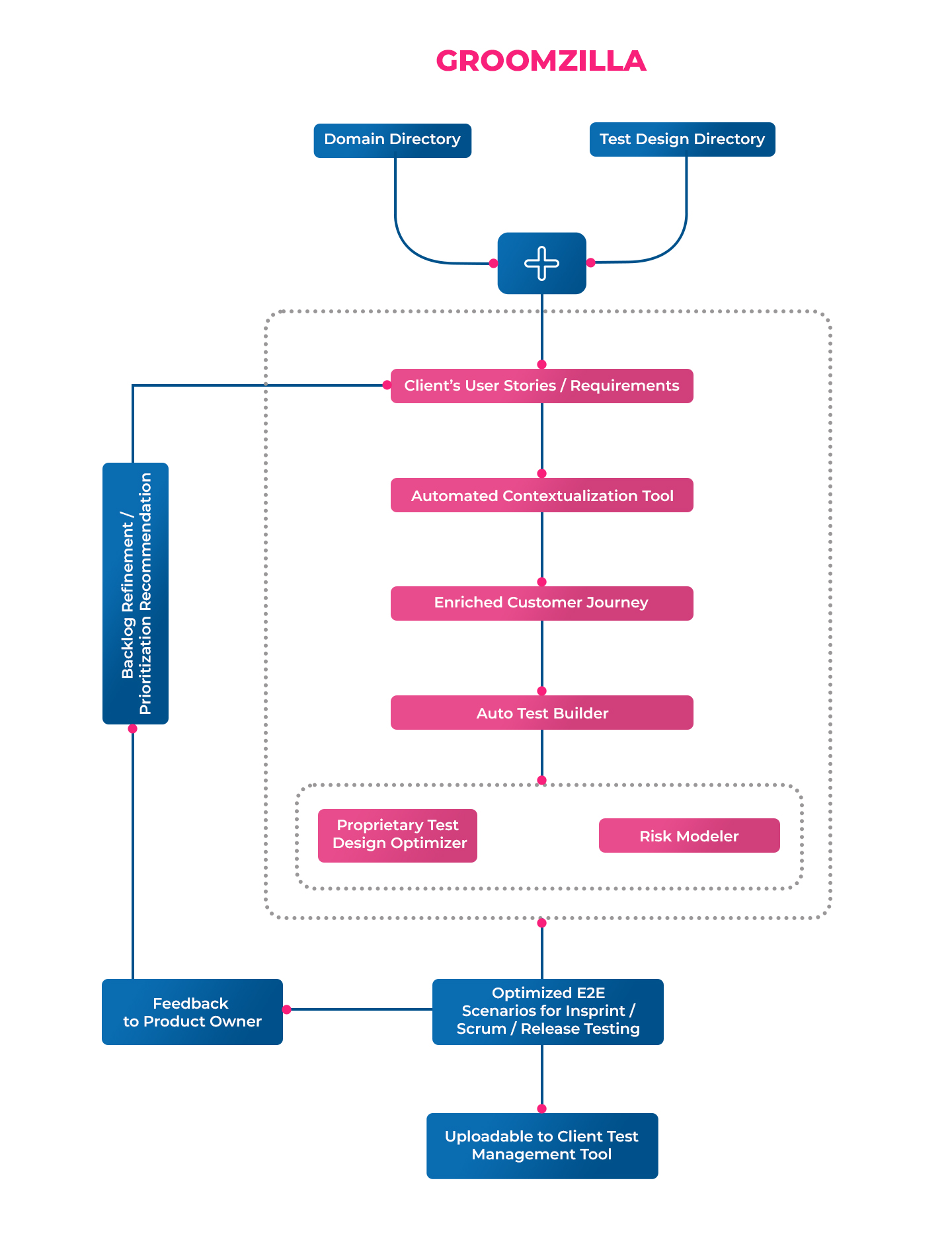
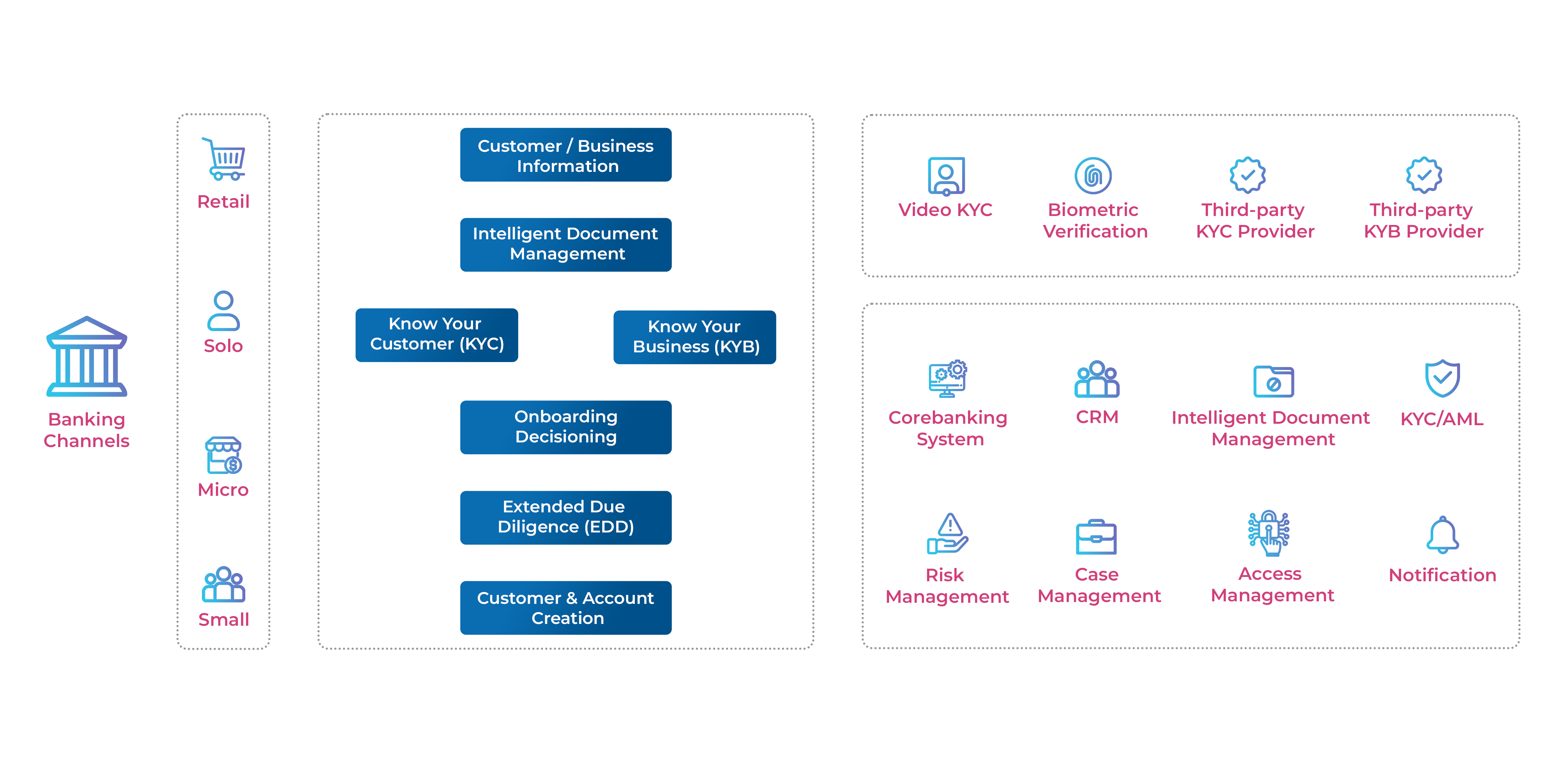
Introduction
FIs have been at the center of technology adoption and are pioneers in using new-age technologies such as AI, ML, Advanced Analytics, and more. Their utilization of these technologies evolves, as today’s customers are highly sophisticated and adopt rapid digitization in all aspects of life.
In the early 1990s, Bill Gates said, “Banking is necessary, Banks are not.” We now realize what he meant then. The new-age customer wants ubiquitous banking services, anywhere, anytime, and from any device! Product-centric banking has become a passe in an era of customer-centric banking. Omnichannel is gaining popularity and is no longer a privilege but a necessity; the failure to adopt can be suicidal for banks. FIs continuously use technologies to analyze, understand and build strategies that help them better serve their customers in line with their current needs and preferences.
Banks have moved from being a store of value to a store of trust to a store of critical information.
Valued at $4.93 billion in 2021, data analytics in the banking market is estimated to grow at a CAGR of 19.4% to reach $28.11 billion by 2031. Data-driven banking is no longer a fancy new concept and has amassed tremendous importance gradually. Data translates to the trust between the banks and their customers, entrusting the former with sensitive information. It is this trusted data that fuels the gamut of banking.
Banks and FIs have begun to realize the invisible curtain that clouds what they think the map of the customer journey should look like from what the customer wants to experience. This reality can be easily deciphered from the digital trail that a customer leaves behind across multiple touch points such as websites, mobile apps, social networks, digital transactions, and much more. It contains rich data that can quickly help banks chart a customer’s journey and predict their engagement regarding the when, where, and how. Banking is now more about providing a super personalized customer experience. Some of the key areas where data analytics can be leveraged in a customer’s banking journey are:
- Acquiring new customers with enhanced prospecting capabilities
- Predict a customer’s needs ahead of requirements realization by the customer.
- Analyse potential areas where the customer would require support.
- Risk assessments on the go, using extremely large data sets to prevent bad debts without being extremely risk-free and underserving the needy.
- Optimize pricing for relevant products/services through a segment-of-one approach.
- Retention strategies to change behaviors and negate potential customer attrition.
Data analytics can transform the banking business for good and build robust customer relationships based on transparency and trust. It is a fact universally accepted across the banking and financial services industry, be it global players or regional and small-sized super local FIs. Several players have begun to utilize decision intelligence platforms to provide contextual services and solutions laced with empathy to humanize the experience in this tech-driven era. One such example is the recent collaboration of US Bank with Adobe to provide a more personalized experience for its consumer banking customers, in-branch and online. With the Adobe Experience Platform, US Bank can provide more personalized experiences that evolve with customer expectations, having a single view of the customer while combining offline and online data.
Challenges of using data analytics in banking
Data quality and integrity: Advanced analytics and the use of ML and AI algorithms are premised on high-quality data. Poor-quality data can result in inaccurate insights and decisions. When the petabytes of data are not validated, profiled, standardized, and purified, it can result in conflicting, outdated, or inaccurate information, impacting data integrity. Imagine the outcome when such low-quality data is fed into the machine learning algorithms! The lack of a single source of truth can prove very costly for banks and lead to a loss of opportunities to deliver superior customer experience. Many banks end up doing an expensive catchup game or, worse still, give up being data enabled. Without accurate data, digital banking is a myth.
Siloed data sources and assets with legacy infra: New-age customers use multiple touchpoints for their baking needs and multiple digital assets (many through external partners). It translates to data residing across disparate systems. Challenged with legacy infrastructure and lack of capabilities to communicate with each other, this results in sub-optimal analytics and inefficient inferences from elegant algorithms. Data integration is another area often overlooked and results in lower RoI.
Digital transformation fatigue: Even before the onset of the pandemic, digital transformation became necessary to stay customer-centric and ahead of the competition. This digital transformation journey has now become a never-ending race. Several banks have been shepherding their digitization journey on a piecemeal basis, and many more are losing momentum with their transformation. They are unable to keep up with the pace of innovation along with the demand for newer services and solutions that are also personalized. Many banks are increasing their costs while trying to optimize budgets by not investing in the requisite processes and data infrastructure. Banking is more digital and less banking. This is irreversible and needs to be respected.
Conclusion
Data analytics is powering banks to steer away from being product-oriented and bring back the customer perspective at the core. As new-age banking customers seek more contextual and super-personalized experiences, data analytics is a must-have for banks. Data analytics and related technology that can facilitate large-scale personalization and compliance with industry rules and regulations are the need of the hour for the banking industry to thrive in the future. They can easily provide the banks with a 360-degree view of the customer and make omnichannel services much more effective. Leveraging data analytics, banks can deliver super personalized customer experiences, establish long-haul customer relationships, and utilize customer analytics to give them a competitive edge.
About the Author
 As an Executive Director at Maveric, Muralee helms the creation of productized solutions that enables Industry-leading CXOs to solve complex challenges across CX, Digital Ops, Connected Core, and Regulatory Compliance. With 24 years of tech leadership experience across Tesco, Altisource, and start-ups like Analyttica Datalabs and Clairvolex IP, Muralee’s contributions have transformed some of the world’s largest mortgage servicing platforms and e-commerce destinations.
As an Executive Director at Maveric, Muralee helms the creation of productized solutions that enables Industry-leading CXOs to solve complex challenges across CX, Digital Ops, Connected Core, and Regulatory Compliance. With 24 years of tech leadership experience across Tesco, Altisource, and start-ups like Analyttica Datalabs and Clairvolex IP, Muralee’s contributions have transformed some of the world’s largest mortgage servicing platforms and e-commerce destinations.
Originally Published in Express Computer