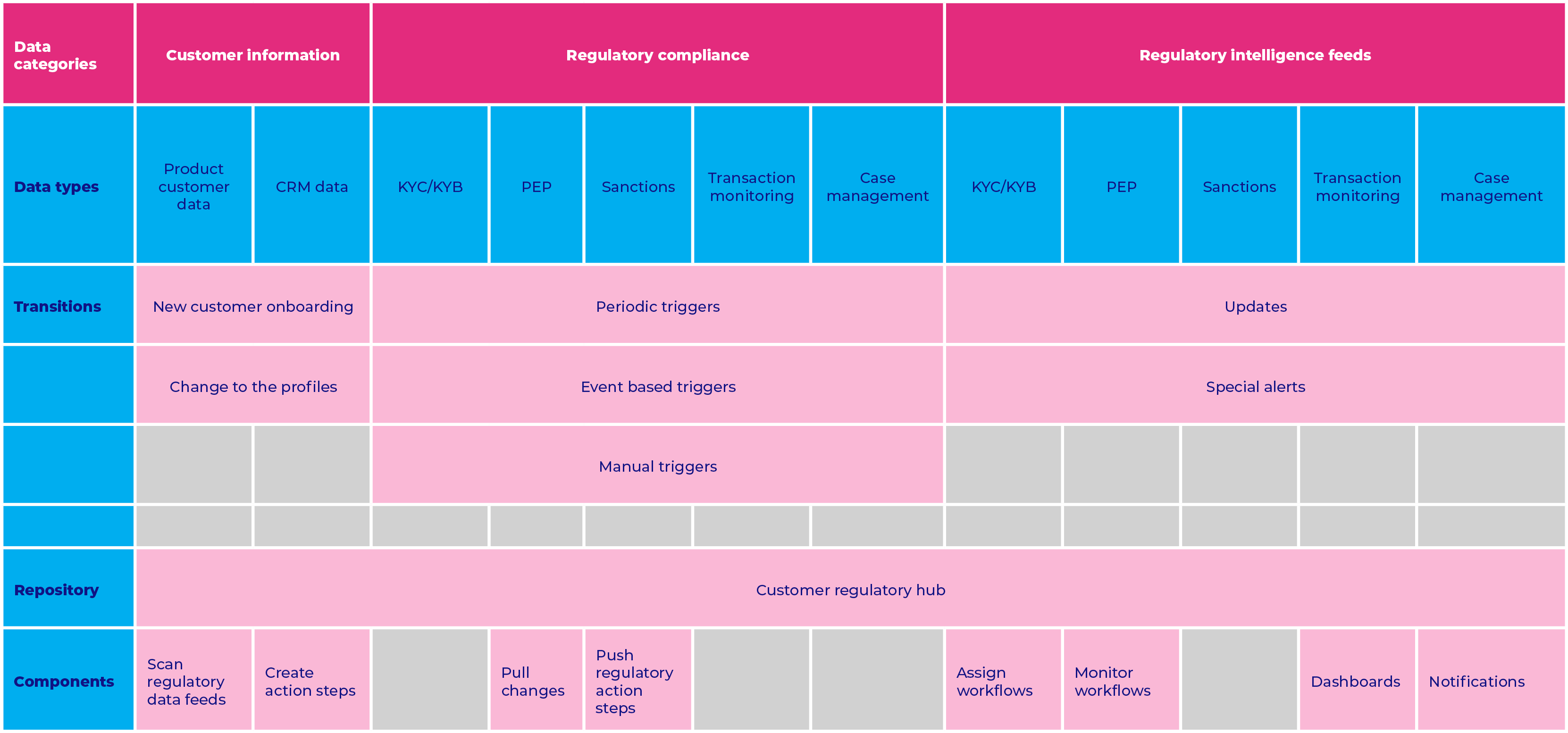
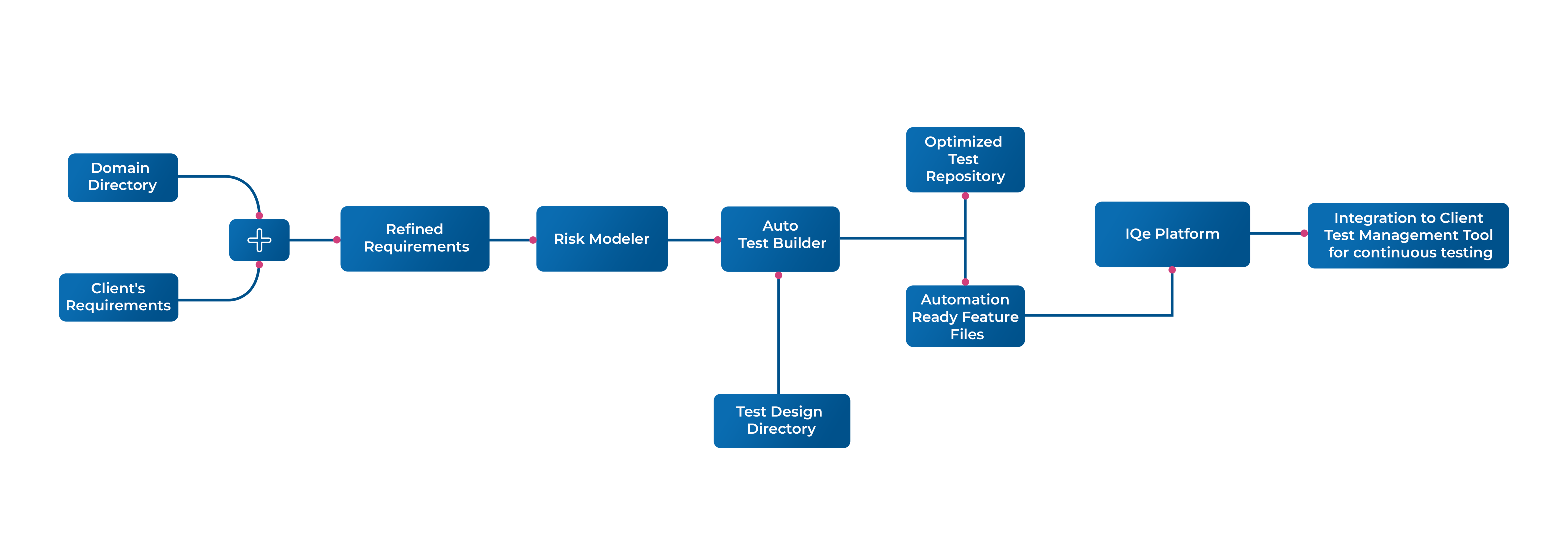
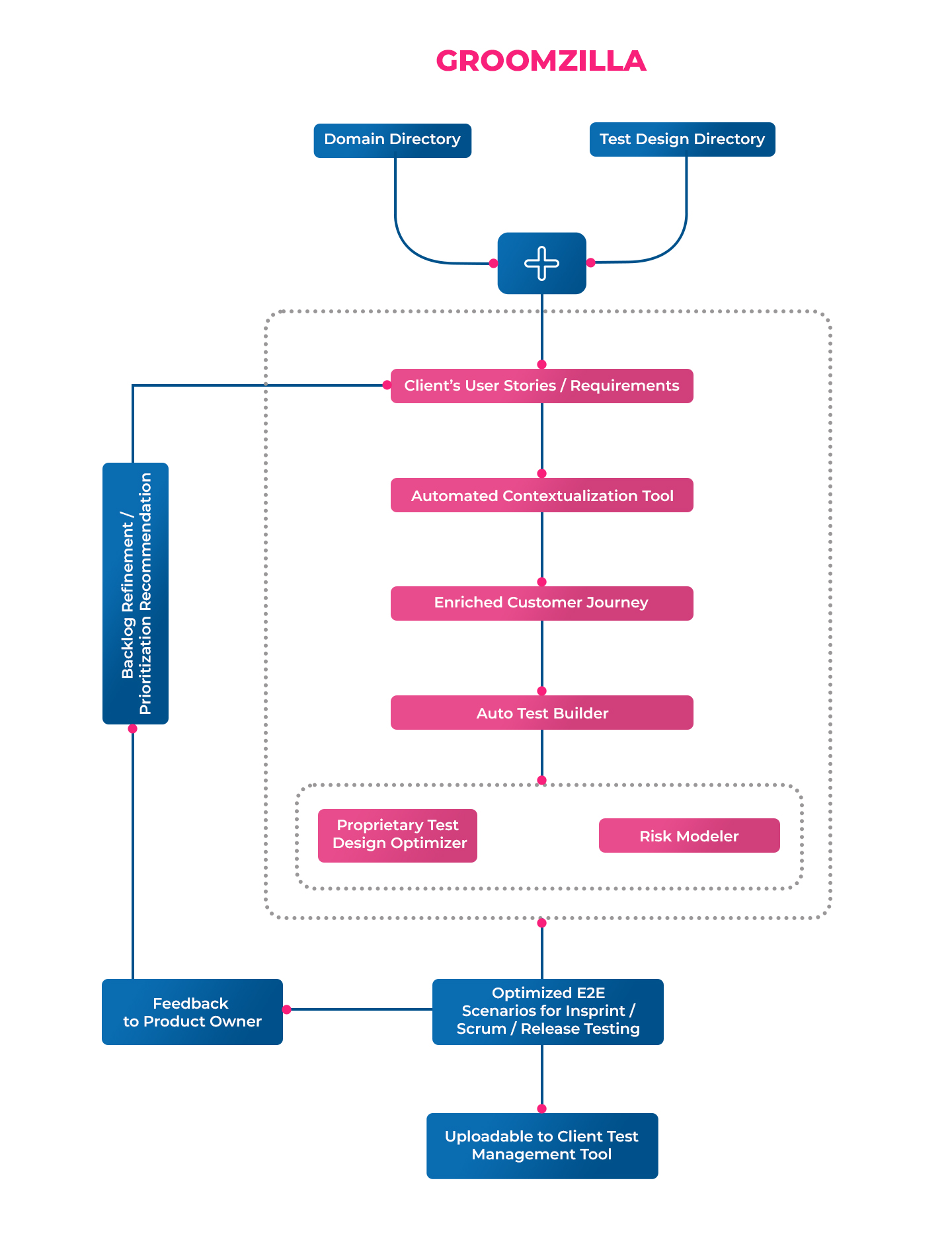
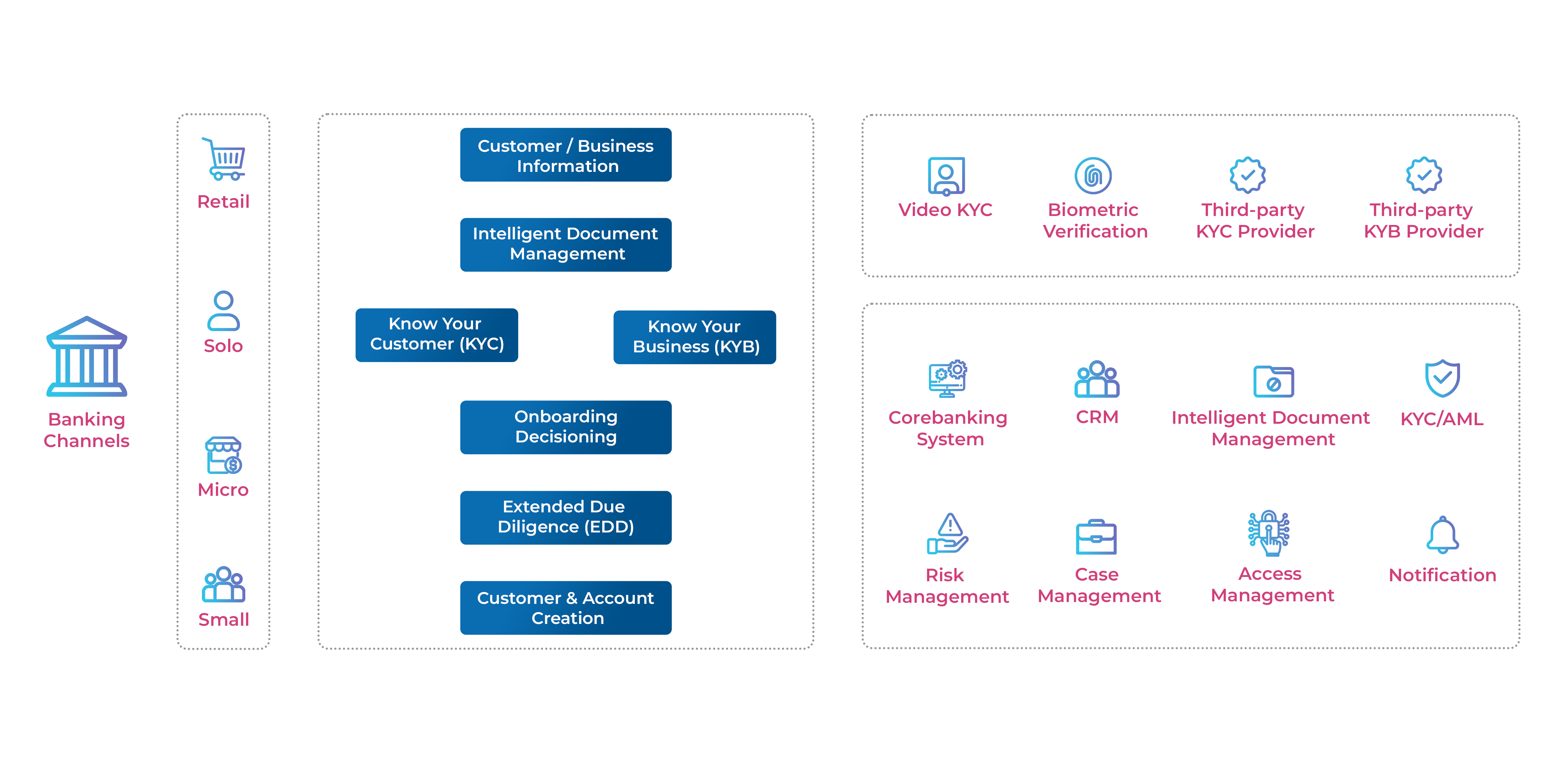
In today’s world, Application Management Services (AMS) organizations have evolved beyond their traditional scope. They have become the melting pot of disciplines, including Application Management, Security Management, Operations Management, and Reliability Management, while also closely working with Platform Engineering. This evolution is a direct result of the digital-first economy, which demands pervasive service availability. Banks recognize this need and have already begun transforming, moving toward a multidisciplinary AMS organization.
Since the emergence of Industry 4.0, technology enablement has significantly influenced revenue growth within the banking industry. Banks are focusing on maximizing their revenues from transaction banking, payments, wealth and asset management, which are becoming increasingly tech-centric. However, this tech-centricity doesn’t come without any downside. According to a research report from EMA, the average cost of IT downtime for enterprises can range from $4,000 to $24,000 per minute, depending on the size of the enterprise. IT downtime leads to loss of customer trust, revenue, reputation, and regulatory fines.
Downtime occurs for multiple reasons, including cyberattacks, inadvertent results of deployments, disasters, and unresolved production issues. Modern AMS organizations have developed a wide range of practices to predict and prevent downtime as well as to respond swiftly when an incident occurs.
Site Reliability Engineering (SRE) ensures enterprise reliability by combining multiple strategies and techniques, including Chaos Engineering, Release Engineering, and Error Budgets. One recommended practice is blue-green deployment, which maintains two identical production environments (blue and green) so that teams can switch instantly between them, thereby minimizing downtime. Another strategy is canary deployments, named after coal miners’ use of canaries to detect toxic gases. In this approach, a small subset of features is released to production for testing stability and preventing downtime in critical environments. Chaos engineering, pioneered by Netflix, introduces controlled chaos to identify blind spots and enhance resiliency through causal analysis. The effectiveness of these strategies is evaluated by system performance under stress, with feedback gathered via observability.
Observability, initially introduced by Rudolf E. Kalman and later popularized in software engineering by Twitter engineers in 2016, has since expanded to include a wide range of telemetry data. AIOps platforms work alongside observability systems by ingesting and analyzing telemetry data, including logs, events, metrics, and traces, to produce actionable insights. With the help of AI, AIOps improves the quality of event correlation, alert noise suppression, root cause identification, and predictability. This enables engineers and operators to investigate issues faster, saving valuable time in incident resolution. Today, observability is essential for detecting both security and operational incidents.
Contemporary AMS organizations leverage Security Information and Event Management (SIEM) and Security Orchestration, Automation, and Response (SOAR) platforms to detect and mitigate security incidents. Historically, Security Operations Centres (SOCs) have operated as centralized units, serving as the primary point of contact for security incidents. However, the role of SOCs is evolving to become more strategic, with security management responsibilities getting increasingly federated and shifted left to the development phase. SIEM platforms aggregate security-related events and logs to identify anomalies, while SOAR platforms employ playbooks to automate incident response.
This complex fabric of tools and practices in modern enterprises often rests on the foundation of Platform Engineering. As a discipline, Platform Engineering develops standardized platforms that comprise tools, infrastructure, and automation for both developers and support engineers. This nurtures enterprise-wide standardization and best practices across the development phase and post-go-live stages of applications and infrastructure.
Imagine this: Platform Engineering is the composer of a symphony — creating structured environments, reusable tools, and best practices that serve as the blueprint for scalable, efficient IT operations.
SRE acts as the conductor, setting the tempo through service-level objectives, enabling automation, and ensuring that operational delivery is reliable, resilient, and efficient.
AMS is the orchestra that brings this symphony to life, managing applications in production, responding to incidents, and continuously improving service quality in tune with the overall architecture. Together, they produce a harmonious experience for the business: reliable systems, minimal downtime, and faster resolution.
Given the direction of AMS evolution, how ready is your organization for an integrated model that combines SRE, AIOps, and Platform Engineering?
FAQ
What are Application Management Services (AMS) for banks?
Application Management Services (AMS) for banks involve a range of processes and practices aimed at maintaining, supporting, and enhancing banking applications to ensure they perform optimally and align with the strategic goals of the bank.
How does Site Reliability Engineering (SRE) help in reducing IT downtime in banks?
Site Reliability Engineering (SRE) involves applying software engineering principles to infrastructure and operations, thus improving scalability and reliability of systems. This approach helps banks in automating responses to system issues, effectively reducing IT downtime.
What role does AIOps play in next-gen AMS for banks?
AIOps, or Artificial Intelligence for IT Operations, leverages machine learning and analytics to enhance IT operations. In next-gen AMS for banks, AIOps can predict and prevent potential failures, optimize system performance, and enhance decision-making processes, thus ensuring smoother operations.
How does Platform Engineering contribute to the effectiveness of AMS in banking?
Platform Engineering in banking involves creating and maintaining a reliable IT platform that supports the deployment and operation of various applications. This discipline ensures that the infrastructure is scalable, resilient, and secure, facilitating more effective application management services.
Why is minimizing IT downtime important in the context of banking AMS?
Minimizing IT downtime is crucial in banking AMS because downtime can lead to significant financial losses, reputational damage, and reduced customer trust. Ensuring high availability and reliability of banking applications is essential to maintain continuous service delivery and client satisfaction.
About the Author
 As Vice President at Maveric, Chandrasekaran Krishnan heads the ‘New Age AMS (Application Management Services)’ service line, bringing deep expertise in managing large-scale AMS programs and shaping outsourcing strategies for global banks. With a strong foundation in service delivery, solutioning, and competency development, he consistently crafts client-focused, opportunity-driven strategies that drive performance. Chandrasekaran’s leadership is marked by a commitment to innovation, inclusivity, and operational excellence, values that align seamlessly with Maveric’s mission to deliver exceptional value to its clients
As Vice President at Maveric, Chandrasekaran Krishnan heads the ‘New Age AMS (Application Management Services)’ service line, bringing deep expertise in managing large-scale AMS programs and shaping outsourcing strategies for global banks. With a strong foundation in service delivery, solutioning, and competency development, he consistently crafts client-focused, opportunity-driven strategies that drive performance. Chandrasekaran’s leadership is marked by a commitment to innovation, inclusivity, and operational excellence, values that align seamlessly with Maveric’s mission to deliver exceptional value to its clients
Originally Published in CXO Today